Chapter 13: Data Storage Structures
File Organization
DB is stored as a collection of DB files. Each file is a sequence of records. Each record is in a sequence of fields. Each relation table is a set of tuples.
The record size is fixed. Each file has records of one particular type only. Different files are used for different relations. A tuple is stored as a record in DB.
Fixed-Length Records
Simple approach
- a block contains several records
- store record \(i\) starting from byte \(n \times (i - 1)\), where \(n\) is the size of each record
- record access is simple but records may cross blocks
- modification: do not allow records to cross block boundaries (contiguous allocation)
Deletion of record \(i\): alternative compacting
- move records \(i + 1\), \(\cdots\), \(n\) to \(i\), \(\cdots\), \(n - 1\)
- move record \(n\) to \(i\)
- do not move records, but link all free records on a free list
“Fixed-Length Records”并不是指现实中每个字段的语义长度恒定不变,而是指“数据库在磁盘/页上为每条记录分配了一个固定的字节长度”。
当我们尝试删除某些 fixed-length records 时,可以使用 free lists。这个表在其 header 中存储第一个会被删除的 record 地址,然后我们再使用第一个会被删除的 record 存储第二个会被删除的 record 地址,以此类推(类似 pointers)。这也说明了,records can be stored in noncontiguous space。
Variable-Length Records
Variable length records arise in several ways:
- Record types allow variable lengths, e.g. strings(varchar).
- Multiple record types in a file. e.g. Multitable Clustering File.
So how to store variable-length records in block?
- Attributes in the record are stored in order (step 1: fixed-length attributes, step 2: variable-length attributes).
- Variable length attributes represented by fixed size (offset, length), with actual data stored after all fixed length attributes.
- Null values represented by null-value bitmap.
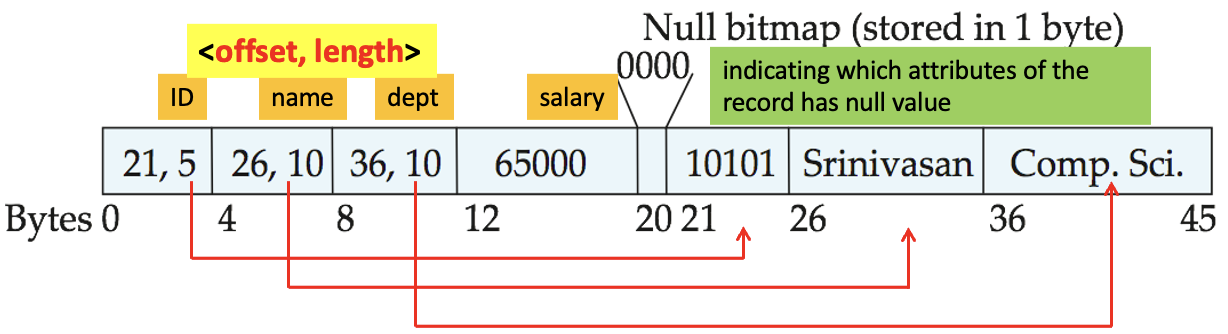
Slotted Page Structure
The storage space is divided into fixed-sized slotted pages, \(4\) KB or \(8\) KB records are allocated to slotted pages.
分槽页结构:将 DB 文件存储空间在逻辑上为多个 page,每个 page 由多个 slot 组成。
- Slotted page header contais
- Number of record entries.
- End of free space in the block.
- Location and size of each record.
- Records can be moved around within a page to keep contiguous.
- \(r_{i}\) is deleted, and \(r_{i + 3}\), \(r_{i + 2}\), \(r_{i + 1}\) are moved to the free space created by deletion.
- Entry in the header must be updated, e.g. set to \(-1\).
- Pointers should not point directly to record, instead they should point to the entry for the record in header.
Organization of Records in Files
DB file can be viewed as a set of records at logical level. Logical organization of records determine how to access the records. These records are logically organized as heap, sequential, hash and clustering.
*Heap File Organization
Any record can be placed anywhere in the file where there is space for the record. Data has no primary keys and no index.
- There is no ordering of records.
- Records usually do not move once allocated.
- There is a single file for a relation.
Free space map
- array with \(1\) entry per block
- each entry records fraction of block that is free
- for example, \(3\) bits (\(0\)-\(7\)) per block, value divided by \(8\) indicates fraction of block that is free
| block | 0 | 1 | 2 | 3 | 4 | 5 | 6 | … |
|---|---|---|---|---|---|---|---|---|
| value | \(4\) | \(2\) | \(1\) | \(4\) | \(7\) | \(3\) | \(6\) | \(\cdots\) |
- block 0: \(4/8 = 50\%\) free
- block 4: \(7/8 = 87.5\%\) free
Second level free space map. For example, each entry stores maximum \(4\) entries of first level free space map.
Sequential File Organization
Records are logically ordered by search keys. Records are stored in sequential order, based on the search key.
- Records are physically stored in search-key order.
- As close to search-key order as possible to minimize the number of block accesses in sequential processing.
Chain together records by pointers.
- The pointer in each record points to the next record in search-key order.
- Sequential access to the file.
Some operations in sequential file organization
- deletion: use pointer chains
- insertion: locate the position where the record is to be inserted
- if there is free space insert here
- if no free space, insert the record in an overflow block
- in either case, pointer chain must be updated
- need to reorganize the file from time to time to restore sequential order.
Clustering File Organization
Store several relations in one file using a multi-table clustering file organization. Records of several different relations are stored in the same file. This is because storing related records on the same block to minimize I/O.
Hashing File Organization
The file records are stored in buckets, and the bucket number is the address of the record. Hash function on some attributes (search key) determine the address of the records. The result of the function specifies in which block/bucket of the record should be placed.
Data Dictionary Storage
Data dictionary stores
- Metadata: data about data, such as
- names of relations
- names, types and lengths of attributes
- names and definition of views
- integrity constraints
- User and accounting information.
- passwords.
- Statistical and descriptive data.
- number of tuples in each relation.
- Physical file organization information.
- How relation is stored (sequential/hash/…).
- Physical location of relation.
- Information about indices.
Relational representation is a specialized data structure designed for efficient access in memory.
Data Buffer
A DB file is partitioned into fixed-length storage units, called blocks. Blocks are units of both storage allocation and data transfer. DBS seeks to minimize the number of block transfers between the disk and main memory. We can reduce the number of disk accesses by keeping as many blocks as possible in main memory.
Def. Buffer is a portion of main memory available to store copies of disk blocks.
Def. Buffer manager allocates buffer space in main memory.
The buffer size is an adjustable parameter. It has impact on the system performance, e.g. throughput.
Buffer Management
Program (requester) calls on buffer manager when need block from disk.
- If the block is already in buffer, buffer manager returns the address of the block in main memory.
- If the block is not in buffer, buffer manager
- Allocates space in buffer for the block
- Replacing (throwing out) some other block, if required, to make space for the new block.
- Replaced block written back to disk only if it was modified since the most recent time that it was written to/fetched from disk.
- Reads the block from disk to buffer and returns the address of the block in main memory to requester.
- Allocates space in buffer for the block
Buffer Replacement Strategy
- Pinned block: memory block that is not allowed to be written back to disk.
- Pin done before reading/writing data from a block.
- Unpin done when read/write is complete.
- Multiple concurrent pin/unpin operations.
- Shared and exclusive locks on buffer.
- Concurrent operations for shared data.
- Reading require shared lock.
- Updating require exclusive lock.
- Locking rules:
- Only one process can get exclusive lock at a time.
- Shared lock cannot be concurrently with exclusive lock.
- Multiple processes may be given shared lock concurrently.
Buffer Replacement Policies
Replace the block least recently used (LRU strategy)
- Idea: use past pattern of block references as predictor of future references.
- Use information in user’s query to predict future references.
Toss-immediate strategy: free the space occupied by block as soon as the final tuple of that block has been processed.
Most recently used (MRU) strategy: pin the block currently being processed. After the final tuple of that block has been processed, the block is unpinned, and it becomes the most recently used block.
- Buffer manager can use statistical information regarding the probability that a request will reference a particular relation, e.g. data dictionary is frequently accessed.
- Heuristic: keep data-dictionary blocks in main memory buffer. (chapter 16)
- Buffer manager may reorder writes
- Lead to corruption of data structures on disk.
- Heuristic: Careful ordering of writes. (chapter 16)
Column-Oriented Storage
Column-Oriented Storage known as colunmar representation. It stores each attribute of a relation separately.
Benefits:
- Reduced IO if only some attributes are accessed.
- Improved CPU cache performance.
- Improved compression.
Drawbacks:
- Cost of tuple reconstruction from columnar representation.
- Cost of tuple deletion and update.
Columnar representation found to be more efficient for decision support than row-oriented representation. Row-oriented representation preferable for transaction processing.
Data Organization in DBS
DBS provides the services of data organization and access. From DBS users, data is organized as relational tables, tuples, and attributes (user-oriented logical organization of data); From operating systems, data is stored as OS file, known as DB file.
DBS 数据的基本逻辑单位——元组/数据行与 OS 文件中数据的基本逻辑单位——文件记录的对应关系。
- 1 个元组对应于文件系统的 1 个逻辑记录
- 1 个关系表对应于 1 个 OS 文件,或 1 个文件存储多个关系表的数据。
在 DBS,1 个 block 包含多个文件逻辑记录。
Data Access in DBS
小型关系数据库系统,关系表被存储在单独文件,DBMS 利用 OS 文件系统作为 DBMS 物理层实现基础,利用 OS 文件系统实现数据组织与访问
- 操作系统为 DB 分配所需的磁盘 block,有可能将逻辑上相邻数据分配到磁盘上不同区域,导致连续访问效率下降。
- 用户对 DB 文件数据的访问需要借助于 OS 文件系统提供的文件结构和存取路径,这也说明 DBMS 对 OS 依赖太大,不利于数据库系统的移植。
- DBS 数据访问过程,DBMS 的 storage management,OS 文件系统,I/O 子系统完成如下地址变换
- DB 关系表中元组/数据行到 DB 文件数据的逻辑地址(文件名,记录号)间的映射。
- DB 文件记录号到外设上数据物理地址(记录所在的物理块号和具体地址)的映射。
现代大型关系数据库系统,SQL Server、Oracle,为适应数据动态变化、提供数据快速访问路径,DB 数据仍然以DB 文件的方式存在,但对 DB 文件管理并不直接依赖于 OS 文件系统。创建数据库时,DBMS 向 OS 一次申请所需外存空间(数据库文件),在此外存存储空间中,DBMS 独立地为数据库中的数据设计存储和访问结构,
- 分配管理 DB 文件,提供数据访问机制。
- 根据需要,动态扩充、压缩数据库空间
SQL Server 中,一个数据库由用于存储表和索引的磁盘/外存存储空间构成,这些空间被分配在一个或多个操作系统文件上(主文件,辅文件,日志文件)。数据库被划分为许多逻辑页,每个逻辑页大小为 8KB。
- 每个数据库文件由多个从 0 开始连续编号的页组成。每个页逻辑上划分为许多从 1 开始连续编号的槽,每个槽用于存放一个数据库表中的数据行/元组/记录。
数据库文件所在的页可以物理上存储在外存连续区域,如想连续的 disk blocks,也可以存储在非连续的 blocks 中。
对于 1 个 DB 表中的数据行/元组/记录,SQL Server 用该表所在的数据库文件 ID、数据行所在页 ID 和 槽 ID 来标识,数据行的逻辑地址:<文件 ID,页 ID,槽 ID>。
SQL Server 以盘区为单位,为 DB 文件的页分配外存上的物理空间。盘区大小为 64KB,占用 8 个连续的页。DB 文件中数据行/元组/记录物理地址:数据行所在盘区的物理地址。
SQL Server 利用全局分配映象 GAM 和共享全局分配映象 SGAM 数据结构记录每个盘区的使用情况。
SQL Server 利用索引分配映象 IAM 数据结构记录每个数据库文件的页与该页所在物理盘区的对应关系
SQL Server 利用索引实现对关系表中的数据行/元组的访问
- Index:search key \(\to\) <文件 ID,页 ID,槽 ID>
- SQL Server 可对关系表的主键自动建立索引
SQL Server 数据存储与访问机制
- 二级地址映射
- 基于索引的 search key \(\to\) <文件 ID,页 ID,槽 ID>
- 基于IAM的数据行逻辑地址 \(\to\) 数据行物理地址(盘区物理地址)
- 二级地址映射
openGauss 段页式存储管理
Segmentation with Paging.
数据库表空间和数据文件以段-区-页/block的逻辑组织方式,进行存储分配和管理。
- 1 个 database(在一个 tablespace 中)有且仅有一个段空间(segment space),段空间的实际物理存储可以是一个物理文件,也可以拆分存储在多个物理文件上。
- 1 个 database 中所有 table 都从该数据库的空间中分配数据,数据库中表的数目和实际物理文件个数无关。避免当数据库中的表比较多时,数据库存储所在的物理文件也比较多的问题。
Database 中的每张 table 有一个逻辑上的 segment,该 table 所有的数据都存在该 segment 上。
- 每个 segment 会挂载多个 extent,每个 extent 是外存上一块连续的物理页,但 1 个 segment 内的各个 extent 可以是不连续的。
- extent 的大小可是根据业务需求调整,避免碎片带来的存储空间浪费。
段页式文件可以自动扩容,不需要用户手动指定,直到磁盘空间用满或者达到 tablespace 设置的限制。段页式存储不会自动回收磁盘空间。
当某些数据表被删除之后,其在段页式文件中占据的空间,会被保留,即段页式文件中会存在一些空洞,磁盘空间没有被释放,这些空洞会被面后新扩展或者创建出来的表重用。如果不需要重用这些空洞,手动调用系统函数,进行磁盘回收,释放磁盘空间。