随机变量及其分布
随机变量
设随机试验的样本空间为 \(S = \{e\}\),\(X = X(e)\) 是定义在样本空间 \(S\) 上的实值单值函数,称 \(X = X(e)\) 为随机变量。
分布律
设离散型随机变量 \(X\) 所有可能的取值为 \(x_{k}(k = 1, 2, 3, \cdots)\),\(X\) 取各个可能值的概率,即事件 \(\{X = x_{k}\}\) 的概率为
\[ P \{X = x_{k}\} = p_{k}, \quad k = 1, 2 \cdots \]
三种重要的离散型随机变量
0-1 分布
设随机变量 \(X\) 只可能取 0 与 1 两个值,它的分布律是
\[ P \{X = k\} = p^{k} (1 - p)^{1 - k}, \quad k = 0, 1 \quad (0 < p < 1) \]
伯努利试验
设试验 \(E\) 只有两个可能结果:\(A\) 及 \(\bar{A}\),则称 \(E\) 为伯努利试验。设 \(P(A) = p (0 < p < 1)\),此时 \(P(\bar{A}) = 1 - p\)。将 \(E\) 独立重复地进行 \(n\) 次,则称这一串重复的独立试验为 \(n\) 重伯努利试验。其分布律如下:
\[ P\{X = k\} = \binom{n}{k} p^{k} (1 - p)^{n - k},\quad k = 0, 1, 2, \cdots, n \]
记作 \(X \sim b(n, p)\)。
泊松分布
设随机变量 \(X\) 所有可能取值为 \(0, 1, 2, \cdots\),而取各个可能值的概率为
\[ P\{X = k\} = \frac{\lambda^{k} \text{e}^{-\lambda}}{k!}, \quad k = 0, 1, 2, \cdots \]
其中,\(\lambda > 0\) 是常数,则称 \(X\) 服从参数为 \(\lambda\) 的泊松分布,记为 \(X \sim \pi(\lambda)\)。
泊松定理
设 \(\lambda > 0\) 是一个常数,\(n\) 是任意正整数,设 \(np_n = \lambda\),则对于任一固定的的非负整数 \(k\),有
\[ \lim_{n \ to \infty} \binom{n}{k} p_n^k (1 - p_n)^{n - k} = \frac{\lambda^{k} \text{e}^{-\lambda}}{k!} \]
因为 \(\lambda\) 是一常数,所以若 \(n\) 很大,则 \(p\) 会很小,在这种情况下有
\[ \binom{n}{k} p_n^k (1 - p_n)^{n - k} \approx \frac{\lambda^{k} \text{e}^{-\lambda}}{k!}, \quad \lambda = np \]
随机变量的分布函数
分布函数的定义 设 \(X\) 是一个随机变量,\(x\) 是任意实数,函数
\[ F(x) = P\{X \leq x\}, \quad -\infty < x < \infty \]
称为 \(X\) 的分布函数。
连续型随机变量及其概率密度
如果对于随机变量 \(X\) 的分布函数 \(F(x)\),存在非负可积函数 \(f(x)\),是对于任意实数 \(x\) 有
\[ F(x) = \int_{-\infty}^{x} f(t) \text{d} t \]
则称 \(X\) 为连续型随机变量,\(f(x)\) 称为 \(X\) 的概率密度函数,简称为概率密度。
三种重要的连续型随机变量
均匀分布
若连续型随机变量 \(X\) 具有概率密度
\[ f(x) = \begin{cases} \frac{1}{b - a}, &a < x < b \\ 0, &\text{otherwise} \end{cases} \]
则称 \(X\) 在区间 \((a, b)\) 上服从均匀分布,记为 \(X \sim U(a, b)\)。
指数分布
若连续型随机变量 \(X\) 具有概率密度
\[ f(x) = \begin{cases} \frac{1}{\theta} \text{e}^{-x/\theta}, &x > 0 \\ 0, &\text{otherwise} \end{cases} \]
其中 \(\theta > 0\) 为常数,则称 \(X\) 服从参数为 \(\theta\) 的指数分布。
指数分布具有无记忆性,具体如下
\[ \begin{aligned} P\{X > s + t | X > s\} &= \frac{P\{(X > s + t) \cap (X > s)\}}{P\{X > s\}} \\ &= \frac{P\{X > s + t\}}{P\{X > s\}} = \frac{1 - F(s + t)}{1 - F(s)} \\ &= \text{e}^{-t/\theta} = P\{X > t\} \end{aligned} \]
正态分布
若连续型随机变量 \(X\) 的概率密度为
\[ f(t) = \frac{1}{\sqrt{2\pi}\sigma} \exp\bigg\{-\frac{(x - \mu)^{2}}{2\sigma^2}\bigg\}, \quad -\infty < x < \infty \]
其中,\(\mu\),\(\sigma > 0\) 为常数,则称 \(X\) 服从参数为 \(\mu\),\(\sigma\) 的正态分布或高斯分布,记为 \(X \sim N(\mu, \sigma^2)\)
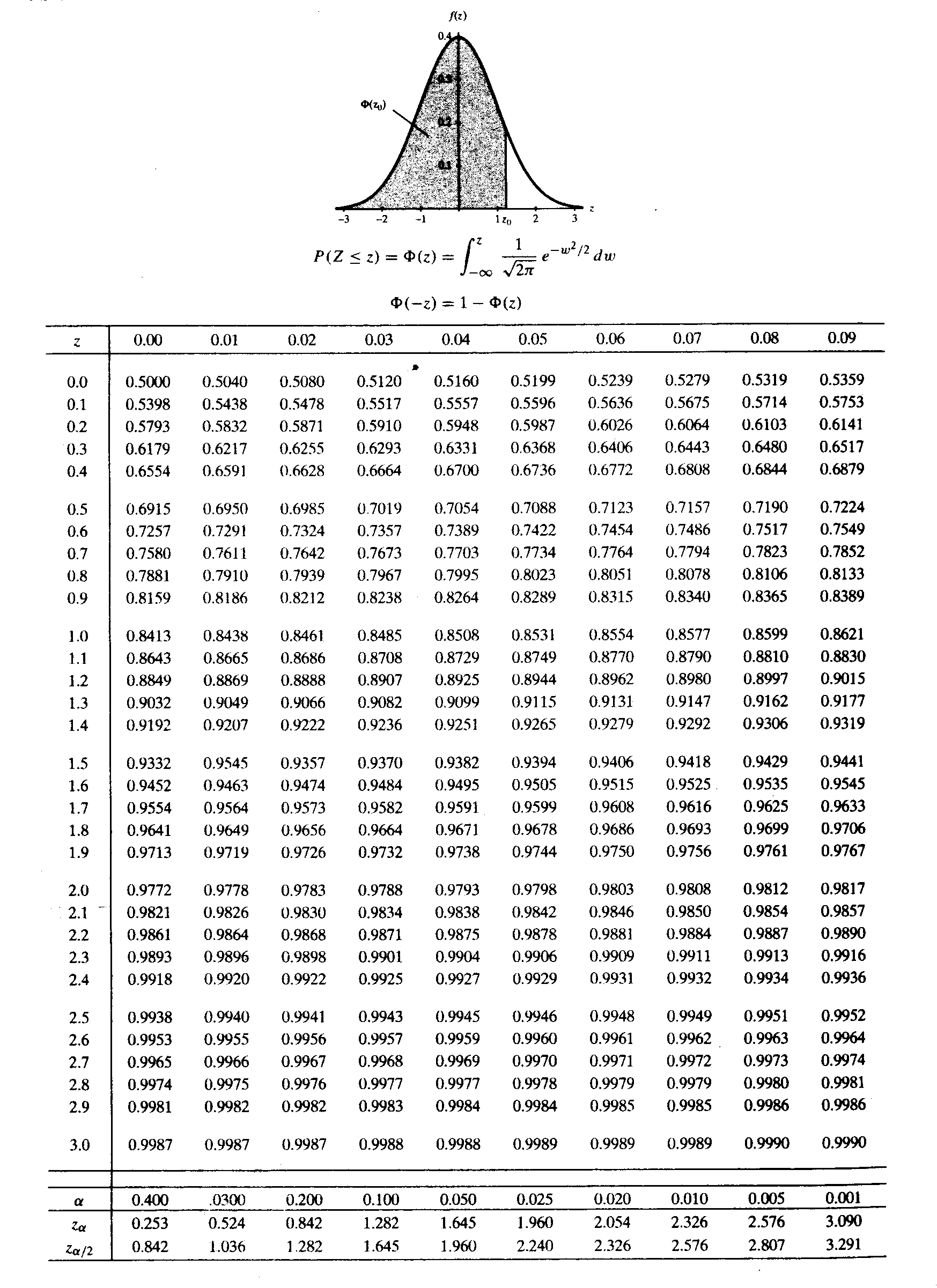
为了便于今后在数理统计中的应用,对于标准正态随机变量,我们引入上 \(\alpha\) 分位数的定义 设 \(X \sim N(0, 1)\),若 \(z_{\alpha}\) 满足条件
\[ P\{X > z_{\alpha}\} = \alpha, \quad 0< \alpha < 1 \]
则称 \(z_{\alpha}\) 为标准正态分布上的上 \(\alpha\) 分位数。
随机变量的函数的分布
设随机变量 \(X\) 具有概率密度 \(f_{X}(x)\),\(-\infty < x < \infty\),又设函数 \(g(x)\) 处处可导且恒有 \(g'(x) > 0\) 或 \(< 0\),则 \(Y = g(X)\) 是连续型随机变量,其概率密度为
\[ f_{Y}(y) = \begin{cases} f_{X} [h_(y)] |h'(y)|, &\alpha < y < \beta \\ 0, &\text{otherwise} \end{cases} \]
其中,\(\alpha = \min \{g(-\infty), g(\infty)\}\),\(\beta = \max \{g(-\infty), g(\infty)\}\),\(h(y)\) 是 \(g(x)\) 的反函数。
补充