7: TLB and Cache
Cache
Concept
- Cache(缓存):存放数据的副本,使常用数据比原始位置更快被访问。
- 目的:加速频繁访问,提升系统性能(适用于架构、操作系统、分布式系统等)。
- 前提:只有在较高的“缓存命中率”下才有效。
- 关键公式:平均访问时间 \(=\) 命中率 \(\times\) 命中时间 \(+\) 未命中率 \(\times\) 未命中时间
Why we need cache?
Processing is often faster than I/O access
Locality
The key to cache success: data access probability.
- 时间局部性(Temporal locality):若某地址被访问,则短期内很可能再次被访问,于是把最近访问的数据保留在靠近处理器的缓存中。
- 空间局部性(Spatial locality):若某地址被访问,附近地址很可能随后被访问,于是将连续的数据块一起提升到上层缓存。
- 要点:利用时间与空间局部性可以提高缓存命中率,从而显著降低平均访问时间。
Memory Hierarchy
- 内存层次(Memory Hierarchy):通过多级存储(从寄存器到磁带)在速度、容量和成本之间权衡,常用数据放在更快但更小/更贵的层次以提升性能。
- 关键收益来自局部性:时间局部性和空间局部性。
- 关键公式:\(平均访问时间 = 命中率 \times 命中时间 + 未命中率 \times 未命中时间\)。
| 层级 | 典型组件 | 典型访问延迟(量级) | 典型容量 | 主要作用 |
|---|---|---|---|---|
| 寄存器 | CPU registers | ≈ 1 ns(最短) | 数十–百字节 | 存放当前运算操作数,最快速访问 |
| On-chip cache (L1) | L1/L0 缓存 | ~1–10 ns | KB–十几KB | 利用时间局部性,快速命中CPU近操作数据 |
| 二级/片上缓存 (L2/L3, SRAM) | On-chip / Second level cache | ~10–100 ns | KBs–MBs | 扩展缓存容量,降低对主存访问 |
| 主存 (DRAM) | Main Memory | ~100 ns | MBs–GBs | 存放程序数据/指令,容量较大但延迟更高 |
| 二级存储 (Disk) | 磁盘/SSD | ~10 ms(磁盘) / 更低(SSD) | GBs–TBs | 持久存储,容量大但延迟高 |
| 三级/更慢存储 (Tape) | 磁带等 | ~10 s(量级) | TBs–PBs | 归档、离线存储,极低成本高容量但访问慢 |
- 要点:通过速度、容量和成本的权衡构建内存层次(Memory Hierarchy),在不同层次用缓存技术提高访问效率。
- 直接利用的缓存技术示例:TLB(页表项缓存)、多级缓存(Cache)、分页虚拟内存(内存作为磁盘缓存)、文件系统缓存、DNS 缓存、Web 代理缓存等。
- 原理:利用时间局部性与空间局部性提升命中率,从而降低平均访问时间。
- 本课程关注的路径:CPU → TLB → Cache → Memory(重点讲解 TLB 与 Cache 的作用与交互)。
TLB
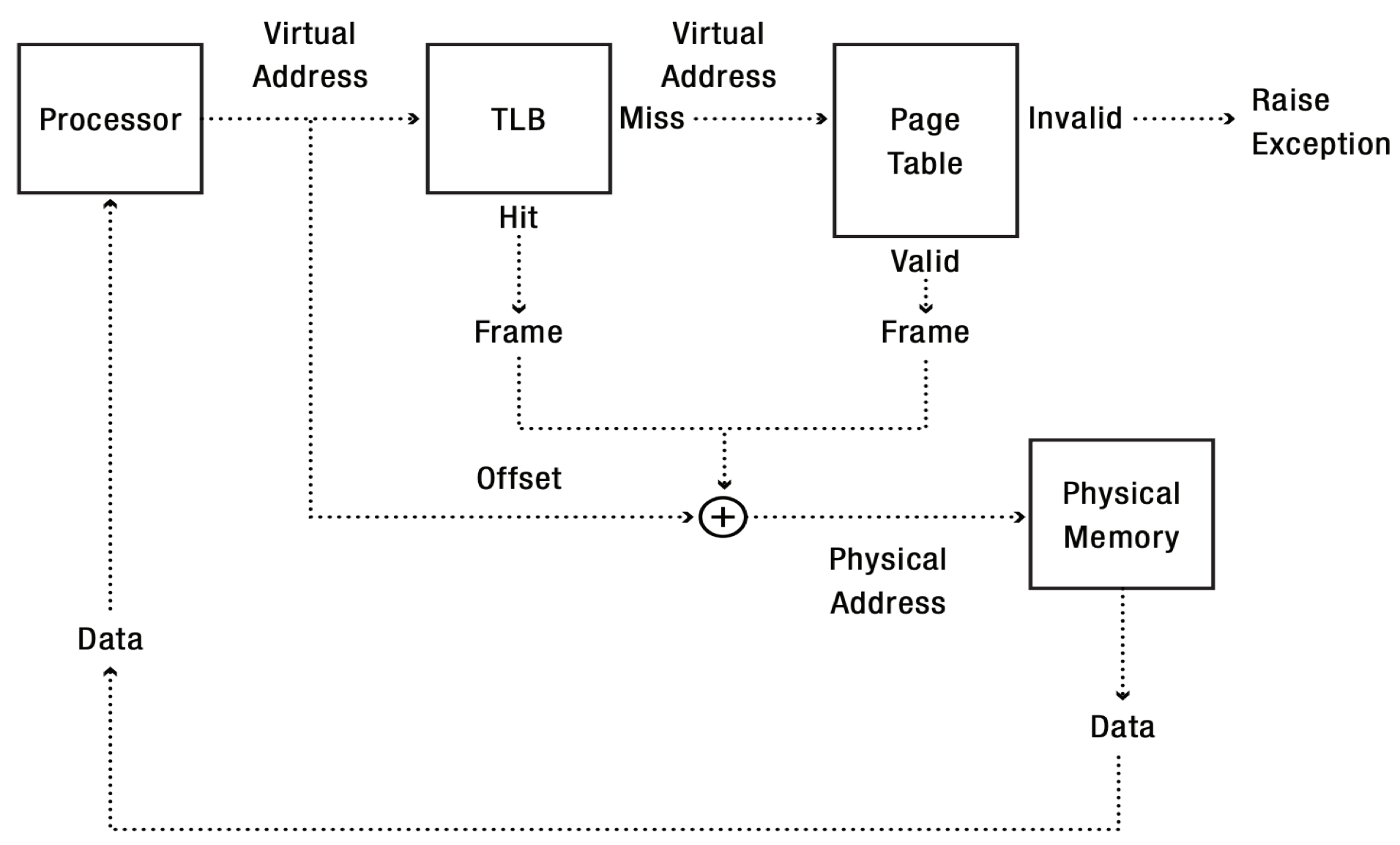
Address Translation Problem
- 问题:虚拟地址到物理地址的多级页表翻译会显著拖慢内存访问。
- 原因:每次内存访问可能需要多次(至少两次)额外的内存访问来查页表;而内存速度通常远慢于CPU,层级越多开销越大。
- 图示:把虚拟地址分成若干索引字段,逐级查页表得到页框,再加上页内偏移形成物理地址,说明多次访存的过程。
- 隐含结论:需要用TLB等缓存页表项的机制来避免频繁的多次内存访问,从而提高性能。
TLB as a Cache
- TLB(Translation Lookaside Buffer,转换检测缓冲区):MMU 内的一个特殊高速缓存,用来缓存页表项以加速地址转换。
- 作用:把虚拟页号直接映射到物理页框,避免每次访问都进行多级页表查找,从而降低地址翻译的延迟。
- 依赖局部性:利用时间局部性(近期访问页)和空间局部性(相邻地址位于同一页)提高命中率。
- 关键点:内存映射按页对齐,TLB 缓存的是页级别的映射条目;TLB 命中能显著减少对主存的额外访存。
TLB Lookup
- 关键流程:MMU 在每次访问时查找 TLB;若任一条目匹配则为命中,直接得到物理页并完成访问;若全部不匹配则为未命中,需做完整的页表翻译并将得到的映射替换进 TLB。
- TLB 条目包含:虚拟页号、物理页框号、访问权限。
- 目的与要点:通过缓存页级映射避免多级页表的多次内存访问,利用时间/空间局部性提高地址转换速度并降低延迟。
TLBs are often set-associative to reduce the comparison.
TLB Miss
TLB 未命中的主要来源概括:
- 该虚拟页此前未被访问(冷启动缺失)。
- 因 TLB 容量有限而被驱逐(替换导致未命中)。
- 由于相联性引发页映射冲突(不同页争用同组)。
- 其它进程或内核修改了页表条目,导致原有 TLB 条目失效。
TLB 未命中(TLB miss)有两种处理方式——硬件遍历页表和软件遍历页表(如 MIPS),两者的流程和结果不同。
- 硬件遍历:MMU 在 TLB miss 时自动走当前多级页表以填充 TLB。若 PTE 有效,硬件填入 TLB,处理器无感知;若 PTE 标记为无效,则产生页错误(page fault),由内核决定后续处理。
- 软件遍历:处理器在 TLB miss 时产生 TLB fault,内核收到异常后遍历页表查找 PTE。若 PTE 有效,内核填充 TLB 并从异常返回;若无效,则调用页错误处理例程。
TLB Performance
关键指标:TLB 命中率(hit ratio)。
提高命中率的两种常用手段:超级页(superpage)和预取(prefetching)。
典型参数量级:
- 大小:\(12\) 位索引 \(\approx 4096\) 条目;
- 命中时间:约 \(0.5\text{–}1\) 个时钟周期;
- 未命中惩罚:约 \(10\text{–}100\) 个时钟周期;
- 未命中率:约 \(0.01\%\text{–}1\%\)(稀疏/图结构应用可达 \(20\%\text{–}40\%\))。
成本公式:
\[ \text{Cost(address translation)} = \text{Cost(TLB lookup)} + \text{Cost(full translation)}\times P(\text{miss}) \]
要点:TLB 小而快,命中率对地址转换总体开销决定性;通过增加页粒度或预取能有效提升性能。
If a TLB hit takes 1 clock cycle, a miss takes 30 clock cycles, a memory read takes 30 clock cycles, and the miss rate is 1%, what’s the average memory access time?
Superpage
- 超级页(Superpage):物理内存中一组连续页,映射到虚拟内存的连续区域,且页对齐,使它们共享同一个高位(超级页地址)。
- 这样可以用一个 TLB 条目缓存整个超级页,显著提升 TLB 命中率。
- 但会牺牲内存分配的灵活性(需要大块连续空间)。
- 匹配方式:只比较地址的高位(超级页地址),忽略超级页内的偏移。
- 2MB 超级页:偏移为虚拟地址最低 21 位。
- 1GB 超级页:偏移为最低 30 位。
- x86 架构对超级页会跳过页表的一级或两级。
- 要点:同一超级页内所有页只需一个 TLB 条目即可命中,减少 TLB 未命中次数,提高性能。
TLB Prefetching
- TLB 预取是指在实际使用前,将页表项提前加载到 TLB 中,以减少未命中带来的延迟。
- 预取方式包括:
- 顺序预取(Sequential):利用空间局部性,适合线性访问。
- 跨步预取(Strided):适用于数组等规律访问。
- 相关预取(Correlated):根据历史访问模式预测下一步访问。
- 预取可由软件或硬件实现。
- CPU 预取的效果与流水线结构密切相关,类似于指令预取。
Memory Performance
| 缓存类型 | 缓存内容 | 缓存位置 | 延迟(周期) | 管理者 |
|---|---|---|---|---|
| Registers(寄存器) | 4-8 字节字 | CPU 内核 | 0 | 编译器 |
| TLB | 地址转换 | 芯片上的 TLB | 0 | 硬件 MMU |
| L1 cache | 64 字节块 | 芯片上的 L1 | 4 | 硬件 |
| L2 cache | 64 字节块 | 芯片上的 L2 | 10 | 硬件 |
| 虚拟内存 | 4KB 页 | 主存 | 100 | 硬件 + 操作系统 |
| Buffer cache | 文件部分 | 主存 | 100 | 操作系统 |
| Disk cache | 磁盘扇区 | 磁盘控制器 | 100,000 | 磁盘固件 |
| 网络缓冲缓存 | 文件部分 | 本地磁盘 | 10,000,000 | NFS 客户端 |
| 浏览器缓存 | 网页 | 本地磁盘 | 10,000,000 | 浏览器 |
| Web 缓存 | 网页 | 远程服务器磁盘 | 1,000,000,000 | Web 代理服务器 |
TLB Consistency
TLB 一致性(Consistency)是所有缓存系统都面临的核心问题:缓存中的内容必须与原始数据保持一致,尤其在条目被修改时。主要涉及以下场景:
- 进程上下文切换(Process context switch):切换进程时需保证 TLB 不泄漏或错误映射其他进程的数据。
- 直接的方法,每次上下文切换直接清空 TLB
- 或者,给 TLB 的结构中新加一个
Process ID的数据
- 权限降低(Permission reduction):当页表权限被收紧时,或者映射被遗弃,TLB 中的旧权限条目必须失效或调整。
- TLB 失效(TLB shootdown):多核系统中,某核修改页表后需通知其他核使相关 TLB 条目失效,确保一致性。
要点:TLB 必须及时同步页表的变更,避免访问到过期或错误的地址映射。
There is nothing to be done with permission addition (e.g. heap/stack extended, read-only to read-write). Why?
- 权限增加后,操作系统会检测到,然后触发异常,接着做一次地址翻译。
Permission Reduction
- 当映射被丢弃或访问权限降低(如从读写变为只读)时,需保证 TLB 条目失效以防止非法访问。
- 早期计算机直接清空整个 TLB;现代系统支持逐条失效(如 x86 的
invlpg指令)。 - 如果页被多个进程共享,处理更复杂。
- 早期计算机直接清空整个 TLB;现代系统支持逐条失效(如 x86 的
- 权限提升(如只读变为读写)无需特殊处理,因为旧条目不会导致安全问题。
- 探讨是否能用硬件自动处理 TLB 失效:
- 处理器无法追踪映射来源,难以判断内存写入是否影响 TLB 条目。
- 即使能做到,频繁检查所有写入也没有必要。
结论:权限降低时需主动失效相关 TLB 条目,通常由软件(操作系统)完成。
TLB Shootdown
- 多处理器系统中,任一处理器修改页表(及其 TLB)时,需让其他处理器的 TLB 也失效(flush),称为 TLB shootdown。
- 具体流程:
- 操作系统先修改页表;
- 向所有处理器发送 TLB flush 请求;
- 完成 TLB 更新的处理器可恢复运行;
- 原始处理器需等待所有处理器确认移除旧条目后才能继续。
- TLB shootdown 的代价随核心数线性增长,可通过批量处理(batch)优化。
要点:多核系统中,页表变更需同步所有核的 TLB,代价高,需优化。
如果初始 CPU 没有等待其他 CPU 的 TLB 失效确认,可能导致同一页被多次读取但数据不一致。
涉及操作系统的异步中断。
现代 CPU 通常包括多个核心,每个核心有其独有的 MMU 和 TLB。
Memory Cache
Fill the speed gap of CPU and DRAM memory.
- 块(block)是缓存的最小单位,通常大于一个字/字节,以利用空间局部性。块大小不能太大也不能太小,现代 Intel 处理器常用 64 字节。
- 地址查找时,地址被分为三部分:Tag(标记)、Index(索引)、Block offset(块内偏移)。
- Index 用于选择缓存集合(Set Select)。
- Block offset 用于选择块内具体数据(Data Select)。
Cache Lookup
缓存(Cache)的查找方式(Cache Lookup)及其三种典型结构:
- 全关联(Fully associative,完全关联):每个地址可以存储在缓存表的任意位置,灵活但查找速度慢。
- 直接映射(Direct mapped):每个地址只能存储在缓存表的一个固定位置,查找速度快但容易冲突。
- N 路组关联(N-way set associative):每个地址可以存储在 N 个缓存集合中的一个,兼顾查找速度和命中率。
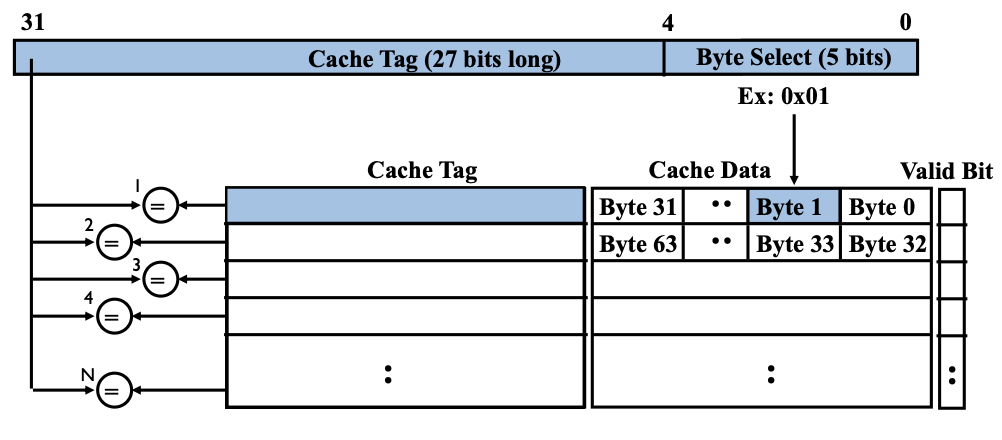
Fully Associative
- 查找方式:每条缓存线都需要比较其 Cache Tag(缓存标记),以判断是否命中。
- 示例参数:块大小为 32 字节(Block Size = 32B)。
- 硬件需求:需要 \(N\) 个 27 位比较器(假设地址高 27 位为 Tag),以并行比较所有缓存行的 Tag。
- 地址分解:地址高位为 Cache Tag(27 位),低 5 位为 Byte Select(块内偏移)。
- 结构说明:每条缓存线包含 Cache Tag、Cache Data(数据块)、Valid Bit(有效位)。
- 查找流程:输入地址后,所有缓存行的 Tag 并行比较,若有命中则通过 Byte Select 选取块内具体字节。
全关联缓存灵活但硬件复杂度高,适合容量较小的高速缓存。
Direct Mapped
Map to one specific cache line through a Hash function.
举个例子:1 KB Direct Mapped Cache with 32 B Blocks
- Index chooses potential block.
- Tag checked to verify block.
- Byte select chooses byte within block.
如何设置 cache index 和 offset 的大小?cache index 的数目等于 cache line 的数目,offset 的数目等于 block size
为什么 cache tag 就是剩下的?首先,cache tag 不能少(这里的不能少指的是,本可以用 22 位但实际只用了 20 位),不然会出现不同 cache tag 命中同一个 cache data。
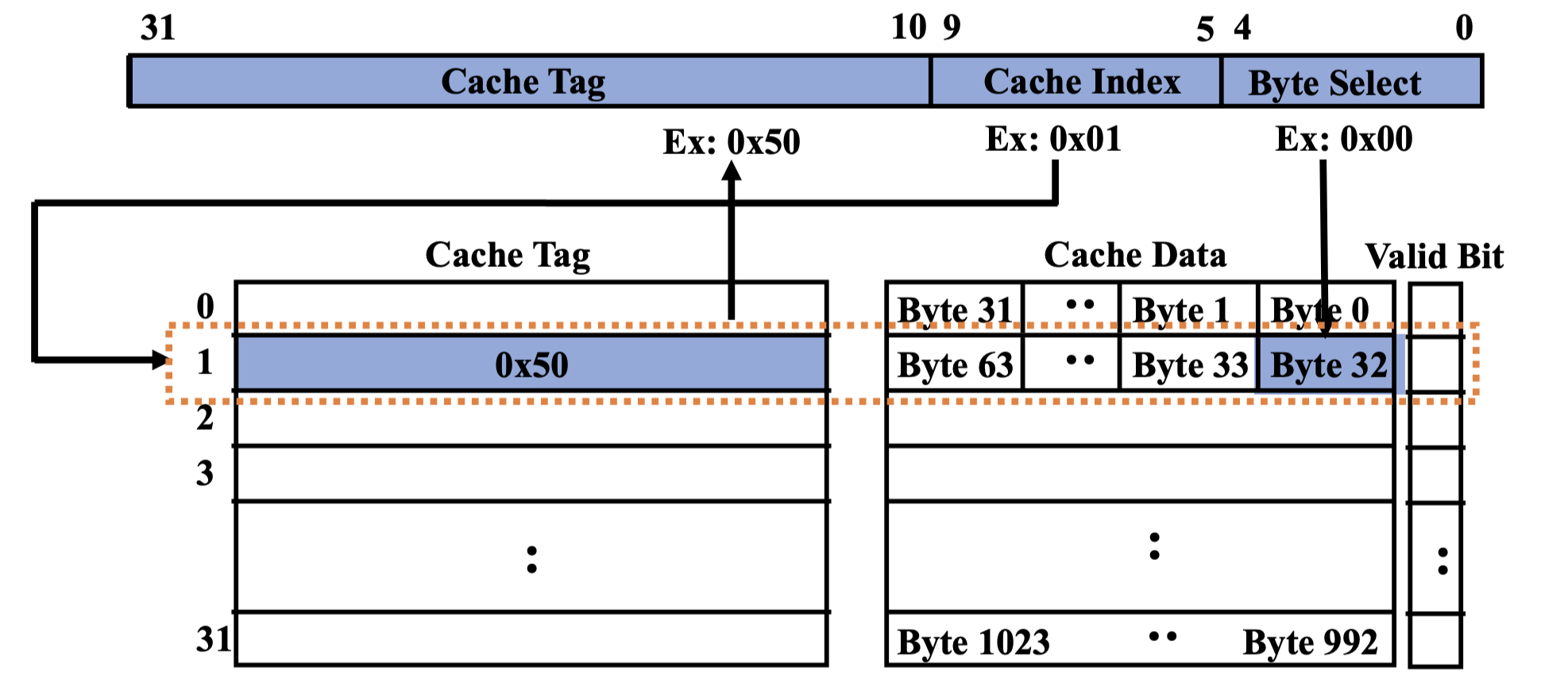
Drawback: frequently using two addresses that map to the same cache entry leads to thrash.
Set Associative
对于每个 Cache Index(缓存索引),组关联允许有 \(N\) 条缓存线(entries)并行参与查找。
一个地址查找时,组内有 \(N\) 个 tag 并行比较。
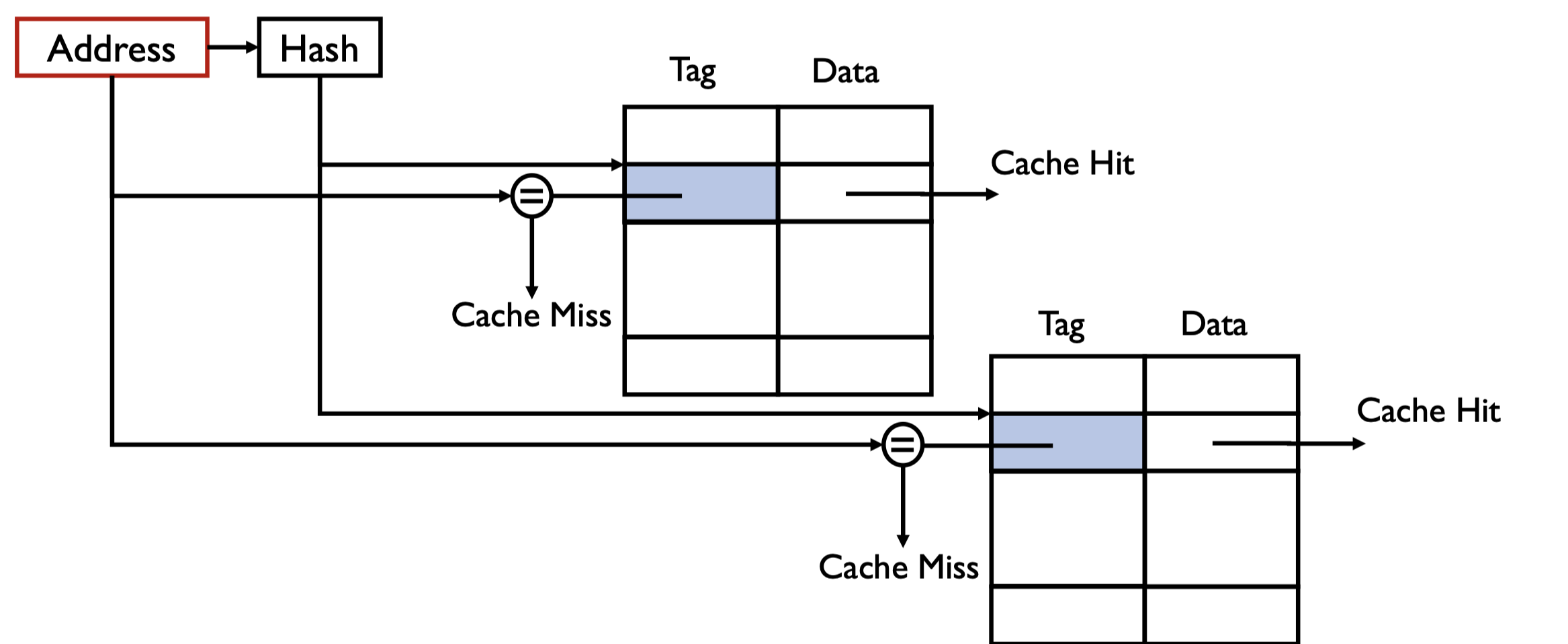
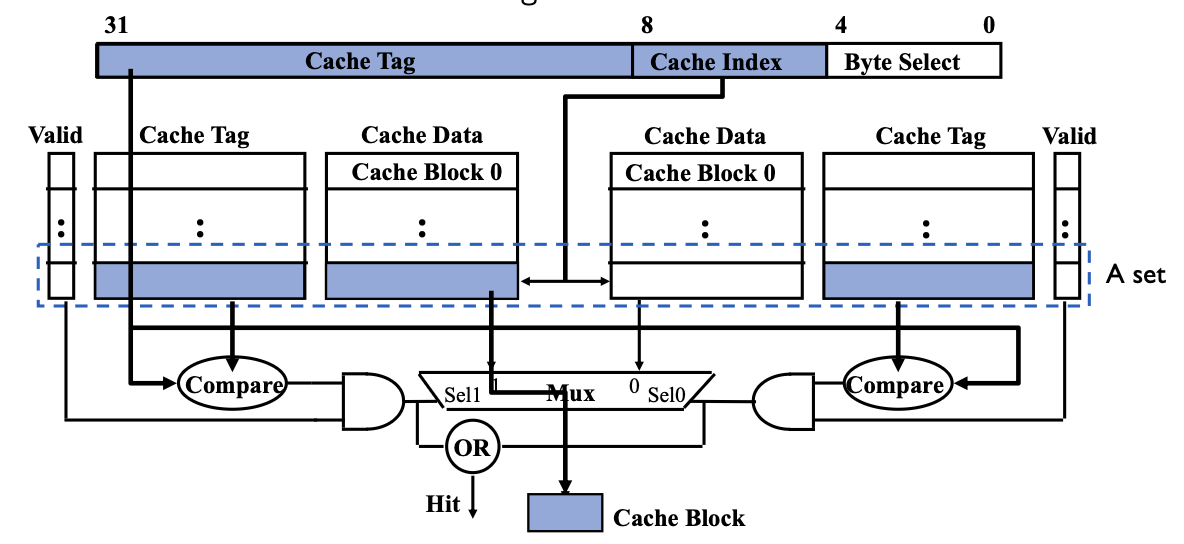
- cache index selects a “set” from the cache
- all tags in a “set” are compared to input in parallel
- data is selected based on the tag result
Why use the lower bits for index, higher bits for tag?
- 空间局部性原理
- 地址的低比特变化快,代表相邻的数据块(如连续字节、连续数组元素)。
- 把低比特作为 Index,可以让相邻地址映射到相邻或同一组缓存线,充分利用空间局部性,提高命中率。
- 高比特唯一性
- 高比特变化慢,代表远距离的数据(如不同数组、不同函数变量)。
- 用高比特作为 Tag,可以区分那些映射到同一组但实际属于不同内存区域的数据,防止冲突。
When \(n = 1\), it becomes directed mapped.
When \(n = \text{cache line}\), it becomes fully associative.
Cache Replacement
Direct mapped(直接映射)
只有一种可能:每个地址只能映射到一个固定的缓存位置,不需要替换策略。Set associative 或 fully associative(组关联或全关联)
一个数据块可以放在多个位置,需要替换策略来决定驱逐哪一个缓存块。常见策略有:- Random(随机):简单,无额外开销。
- FIFO(先进先出):某些场景下效果很差。
- LRU(最近最少使用):根据历史访问预测未来,优先替换最久未被访问的块。
- 记录每个 block 的时间戳
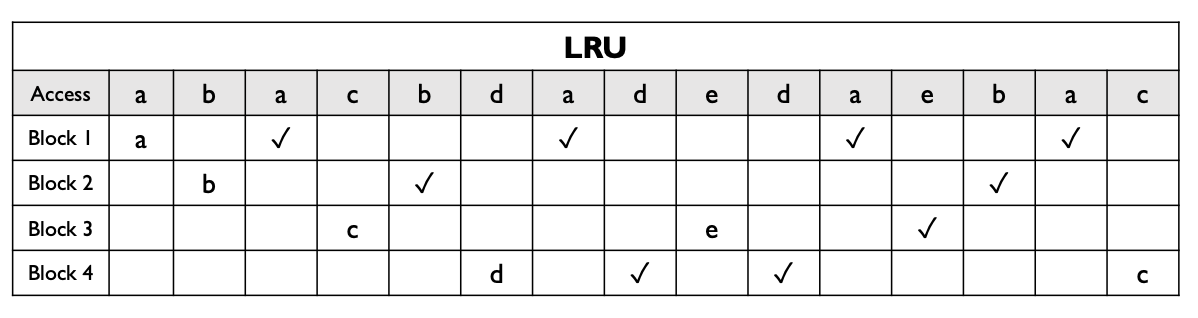
Cache Write Policies
- Write through(直写):数据同时写入缓存和主存。
- 优点:读未命中不会导致写操作。
- 缺点:处理器写入时会被阻塞,除非有写缓冲。
- Write back(回写):数据只写入缓存,只有缓存块被替换时才写回主存。
- 需判断缓存块是否被修改(干净/脏块,dirty bit)。
- 优点:重复写操作不会频繁写入主存,处理器写入时不被阻塞。
- 缺点:实现更复杂,读未命中时可能需要先回写脏数据。
- 缓存(Cache)可以通过虚拟地址和物理地址进行寻址,但实际有多个层级的缓存。
- 所有经过 MMU(内存管理单元)后的地址访问都是物理地址。
- TLB 未命中的代价非常高,因此通常会让 TLB 和一级缓存(L1 Cache)在 CPU 内部重叠,以提升性能。
- 图示流程:CPU 先用虚拟地址经 MMU & TLB 翻译为物理地址,再访问各级缓存和主存。
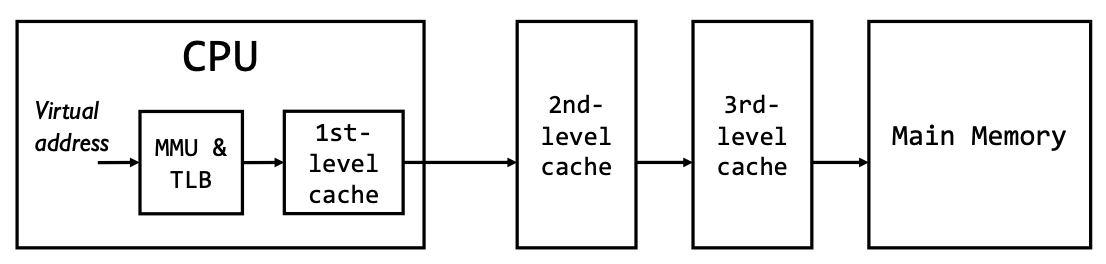
Overlapping TLB and Cache
- 虚拟地址中的 Offset(页内偏移)正好覆盖了 Cache 的 index(索引)和 byte select(字节选择)字段。
- 这样,CPU 可以在地址转换(TLB 查找虚拟页号 \(\to\) 物理页号)的同时,并行选中缓存中的字节,提升访问效率。
实际上,虚拟地址和物理地址的结构为:
- 虚拟地址结构:
[Virtual Page # | Offset]- Virtual Page #:虚拟页号,用于TLB查找。
- Offset:页内偏移,用于定位页内具体字节。
- 物理地址结构:
[tag/page # | index | byte]- tag/page #:物理页号或缓存标记。
- index:缓存索引(决定落在哪个cache组)。
- byte:块内字节选择。
地址翻译时,offset 不变
需确保,\(\text{offset} = \text{index + byte}\)。
下面举个例子,假设虚拟地址的 offset 位有 \(12\) 位,则 index 加上 byte 位数要保证 \(12\) 位,假设其中低两位在物理地址中时 byte,并且缓存机制为 four-way set associative,则缓存大小为 $ 2^{12 - 2} $。此时一个 index 寻址到一个 set,每个 set 有 \(4\) cache line,每个 cache line 有 \(4 \ \text{bytes}\)。
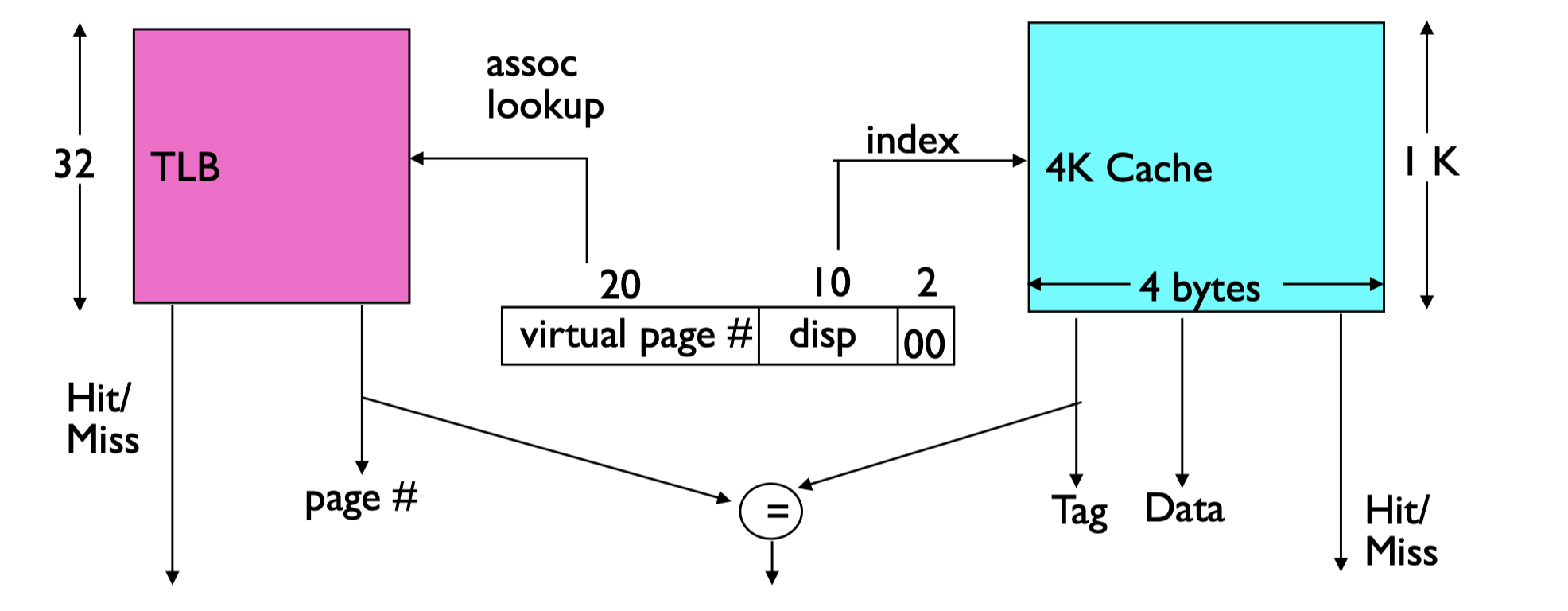
- 虚拟地址结构被分为三部分:虚拟页号(virtual page #,20位)、页内偏移(disp,10位)、块内字节选择(00,2位)。
- TLB 用虚拟页号查找物理页号,判断是否命中(Hit/Miss)。
- Cache 用偏移(disp)作为 index,块内字节选择(00)定位具体字节。
- 两者可以并行查找,因为虚拟地址的 offset 部分直接决定了 cache 的 index 和 byte select。
- 最终,TLB 和 Cache 都命中时,直接返回数据;否则需要进一步处理。
总结:
- 核心思想:虚拟地址中的 offset(页内偏移)正好覆盖了 cache 的 index(索引)和 byte select(字节选择),因此可以在地址转换(TLB 查找)和缓存查找时并行选中缓存字节,加速访问。
- VIPT(Virtually Indexed, Physically Tagged):缓存用虚拟地址索引、物理地址做 tag,常用于 L1 cache。
- 另一方案 VIVT(Virtually Indexed, Virtually Tagged):缓存 tag 也是虚拟地址,只有缓存未命中时才做地址转换,但会带来一致性等问题。
- 实际应用:L1 cache 多为 VIPT,L2/L3 cache 多为 PIPT(Physically Indexed, Physically Tagged)。
仅限于 L1 cache。